Measuring boundary length
Oftentimes we segment an image to find objects of interest, and then measure these objects – their area, their perimeter, their aspect ratio, etc. etc. Measuring the area is accomplished simply by counting the number of pixels. But measuring the perimeter is not as simple. If we simply count the number of boundary pixels we seriously underestimate the boundary length. This is just not a good method. A method only slightly more complex can produce an unbiased estimate of boundary length. I will show how this method works in this post. There exist several much more complex methods, that can further improve this estimate under certain assumptions. However, these are too complex to be any fun. I’ll leave those as an exercise to the reader. :)
Because we will examine only the boundary of the object, the chain code representation is the ideal one. What this does, is encode the boundary of the object as a sequence of steps, from pixel to pixel, all around the object. We thus reduce the binary image to a simple sequence of numbers. In future posts I’ll explain a simple algorithm to obtain such a chain code, and show how to use chain codes to obtain other measures. In this post we’ll focus on how to use them to measure boundary length.
The chain code was first proposed by H. Freeman (IRE Transactions on Electronic Computers 10(2):260-268, 1961), and therefore sometimes referred to as Freeman code or Freeman chain code. A chain code simply gives the steps necessary to walk along all the pixels on an object’s boundary, starting at a random one. Instead of saying “move left”, “move diagonally up and right”, etc., it says simply “4”, “1”, etc. The interpretation of the numbers is trivially explained with a figure:
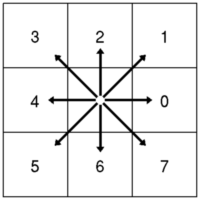
Because we use the chain code to describe an object’s boundary, we will always end up in the same pixel we started: the
boundary is closed. The direction in which we walk is not important, though we will consistently walk clock-wise around
the shape. The sequence [0,1,2,7,0,6,5,7,1,0,0,1] encodes a portion of a boundary as follows:
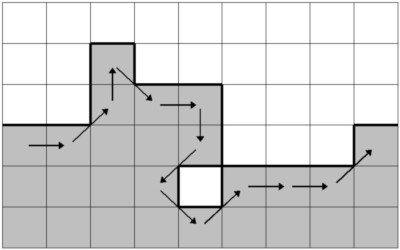
Using DIPimage, the chain code is obtained with the function dip_imagechaincode. It takes a
labeled image, a connectivity value (set this to 2!) and the label ID of the object to get the chain code for.
[Note: this function no longer exists in DIPimage 3, use the traceobjects function instead.]
For example:
img = label(threshold(gaussf(gaussf)));
cc = dip_imagechaincode(img,2,1) % for DIPimage 2
% cc = traceobjects(img,1,2,'chain code') % for DIPimage 3, use cc{1} instead of cc.chain below
So how do we use this code to compute a boundary length? The pixel counting method, of which I said earlier that it significantly underestimates boundary length, is equivalent to the number of elements in the chain:
p = length(cc.chain);
Why does this underestimate the length? Well, diagonal steps (the odd chain codes) are longer than horizontal or vertical steps (the even chain codes). In the original Freeman paper, it is suggested to add √2 for each odd code, and 1 for each even code:
even = mod(cc.chain,2)==0;
p = sum(even) + sum(~even)*sqrt(2);
This computes the exact length of the line that goes from pixel center to pixel center, around the object. However, this is not at all what we are after. The binary shape we obtained through segmentation represents some real-world object, which was sampled and binarized, and it is that object’s perimeter that we want to estimate. It is highly unlikely that that object has the exact same “jagged” outline as our binary shape. Parts of the perimeter that are straight lines at 0, 45 or 90 degrees will be measured correctly, but a straight line at, say, 10 degrees will be overestimated because its binarized representation is jagged. Proffitt and Rosen (Computer Graphics and Image Processing 10(4):318-332, 1979) suggested different weights for even and odd codes, based on a minimum square error for straight lines of infinite length at random orientations:
p = sum(even)*0.948 + sum(~even)*1.340;
Proffitt and Rosen also introduced the concept of corner count, the number of times the chain code changes value. As we will see later, this can further reduce the orientation dependency of the method. Vossepoel and Smeulders (Computer Graphics and Image Processing 20(4):347-364, 1982) obtained the following optimal values using the even, odd and corner counts:
corner = cc.chain~=[cc.chain(end),cc.chain(1:end-1)];
p = sum(even)*0.980 + sum(~even)*1.406 - sum(corner)*0.091;
Let’s now examine these methods with a little experiment. First I’ll generate square objects, rotated at various angles between 0 and 90 degrees, and compute their perimeter with the four methods above:
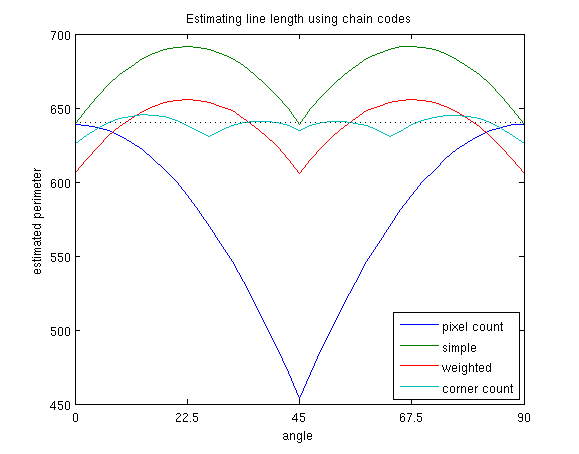
As you can see, the simple pixel counting method works well at 0 and 90 degrees, but severely underestimates the length at other orientations. Freeman’s method is correct at 0, 45 and 90 degrees, but overestimates at other orientations. This is because, as I explained earlier, it follows the jagged line of the discretized shape rather than the straight boundary of the original object. When we use the optimal weights, the graph simply shifts downwards. We are counting both even and odd steps to be slightly shorter. This increases the error for 0, 45 and 90 degrees, but makes the average error smaller, and removes the bias. Finally, when adding the corner count, we add an additional parameter, which means that the measured curve has an additional ripple. This reduces the average error even further.
We can do another experiment to show the effect of sampling density on the measures. It is common to expect the relative error in the estimated perimeter to get smaller as we increase the number of pixels on the perimeter. However, this is only true if the measure is unbiased! Here I’ve generated binary disks and measured their perimeters. The absolute, relative error is plotted in percentages against the disk’s radius ():
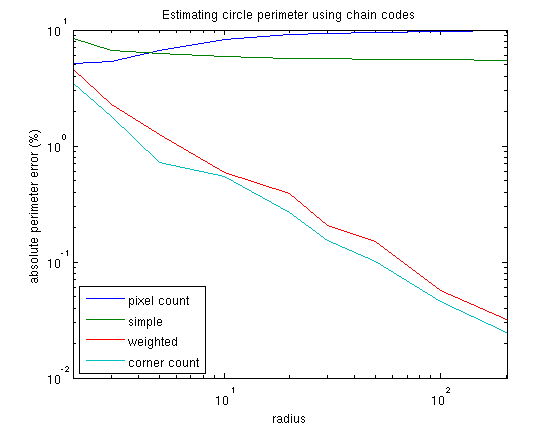
This graph clearly shows that the biased measures do not benefit from a higher sampling density. They make a 10% and 5% error, respectively, starting at a relatively small radius of about 10 pixels. The two unbiased methods, however, do benefit from the increased sampling density, and the error plots do not flatten out until a much larger radius (outside the graph!). The corner count method is only slightly better than the method that doesn’t count corners, because on a circle the errors at all orientations cancel each other out. For other shapes, the corner count method will show a larger advantage.
The code to reproduce the two graphs above can be fetched right here. Remember, it requires MATLAB with DIPimage. [Note: the script was written for DIPimage 2, and will require a small change, as shown in this post, to work with DIPimage 3.]
In future posts I’ll explain the algorithm that extracts the chain code from a binarized object, as well as methods to compute the minimum bounding rectangle and maximum object length, for example. You can even compute an object’s area using only its chain code!